
🧭 Pendahuluan: Nadi dari Dunia yang Diggerakkan oleh Data
Setiap bisnis modern — mulai dari startup hingga perusahaan global — bergantung pada satu hal penting: aliran data.
Namun, data mentah sering kali berantakan, tersebar, dan tidak berguna sampai dikumpulkan, diproses, dan diubah menjadi informasi yang bisa dimanfaatkan.
Di sinilah data pipeline berperan — sistem tak kasat mata yang mengalirkan, membersihkan, dan menata data agar tim analis, data scientist, dan bisnis bisa membuat keputusan yang tepat.
Dalam artikel ini, kita akan membahas bagaimana merancang data pipeline modern yang skalabel, alat apa saja yang digunakan, dan bagaimana semuanya terhubung dari tahap pengambilan data hingga menjadi insight.

⚙️ Apa itu Data Pipeline?
Data pipeline adalah rangkaian proses yang memindahkan data dari satu sistem ke sistem lain, sambil mentransformasinya di sepanjang jalur tersebut.
Bayangkan seperti jalur produksi di pabrik — bahan mentah (data) masuk di satu sisi, dan produk jadi (insight) keluar di sisi lainnya.
Tahapan Umum:
- Ingestion: Mengumpulkan data dari sumber (database, API, IoT, log).
- Storage: Menyimpan data di data lake atau data warehouse.
- Processing: Membersihkan, mentransformasi, dan memperkaya data.
- Serving: Menyediakan data untuk analisis atau machine learning.
- Monitoring: Memastikan reliabilitas dan akurasi pipeline.
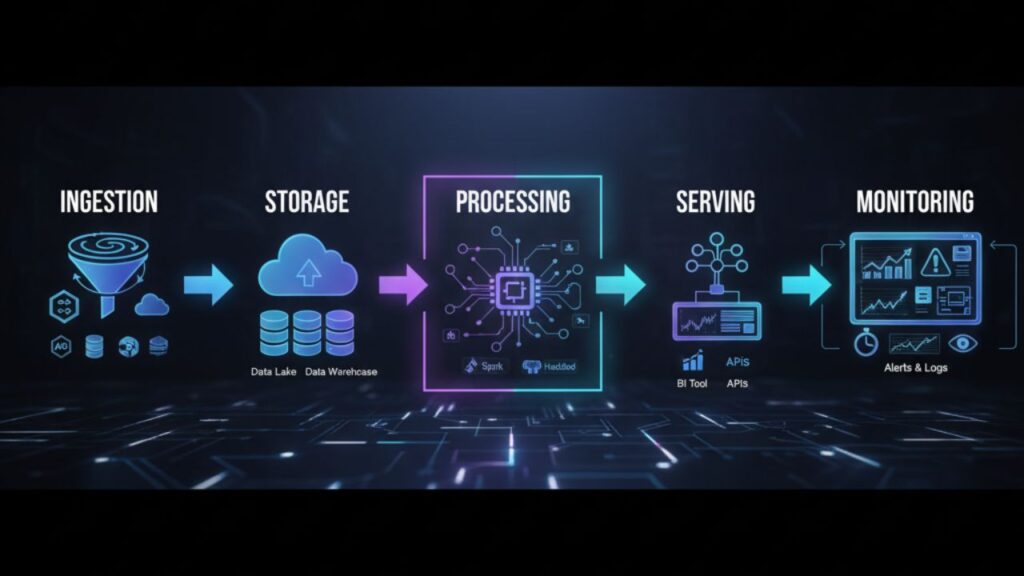
🧩 Komponen Utama Data Pipeline Modern
Data pipeline modern dirancang agar skalabel, otomatis, dan andal. Mari kita lihat tiap lapisannya secara rinci.
1. Data Ingestion
Tahapan ini adalah proses memasukkan data ke dalam sistem.
Terdapat dua jenis utama:
- Batch ingestion: Pemrosesan data secara berkala (contohnya setiap malam dari sistem CRM).
- Streaming ingestion: Pemrosesan data secara real-time (contohnya menggunakan Kafka, Kinesis, Pub/Sub).
2. Data Storage
Data disimpan dalam beberapa lapisan:
- Raw Zone: Data mentah dari sumber.
- Processed Zone: Data yang sudah dibersihkan dan diformat.
- Analytics Zone: Data siap digunakan untuk analisis.
Pilihan penyimpanan umum meliputi Amazon S3, Google Cloud Storage, Azure Data Lake, atau sistem lokal seperti HDFS.
3. Data Transformation
Proses transformasi (ETL atau ELT) digunakan untuk membersihkan dan mengubah data agar sesuai dengan kebutuhan bisnis.
Alat populer: Apache Spark, dbt, dan AWS Glue.
4. Data Orchestration
Mengatur urutan dan waktu eksekusi tugas pipeline.
Alat umum: Apache Airflow dan Prefect.
5. Data Delivery
Tahapan terakhir adalah mengirimkan data ke gudang data (misalnya Snowflake, BigQuery) atau ke alat visualisasi seperti Power BI dan Looker Studio.

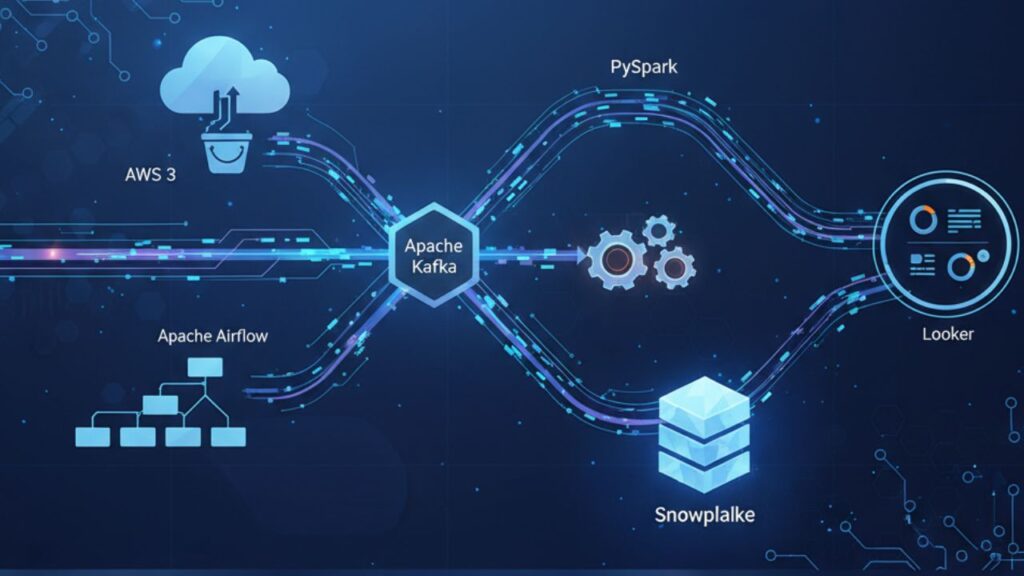
🧮 Contoh Arsitektur: Airflow + Spark + Snowflake
Mari kita rancang arsitektur pipeline yang sederhana, efisien, dan siap cloud.
Contoh Alur Pipeline:
- Ingestion: Kafka mengalirkan data secara real-time.
- Storage: Data mentah disimpan di AWS S3 (Raw Zone).
- Transformation: Spark membersihkan dan mengagregasi data.
- Orchestration: Airflow menjadwalkan seluruh tugas harian.
- Warehouse: Data akhir disimpan di Snowflake untuk BI.
- Analytics: Looker menampilkan hasilnya dalam dashboard interaktif.
Pendekatan ini membuat sistem menjadi modular, mudah diuji, dan tangguh terhadap kegagalan.
⏱️ Batch vs. Real-Time Pipelines
Pipeline dapat berjalan dalam mode batch atau real-time, tergantung kebutuhan bisnis.
| Mode | Kasus Penggunaan | Alat yang umum digunakan |
|---|---|---|
| Batch | Laporan penjualan harian, rekap bulanan | Airflow, Spark, dbt |
| Real-Time | FDeteksi fraud, sensor IoT, perdagangan saham | Kafka, Flink, Kinesis |
Banyak organisasi kini menggunakan arsitektur hybrid — batch untuk data historis, dan streaming untuk analisis langsung.
🔮 Masa Depan Otomatisasi Aliran Data
Pipeline masa depan akan:
- Sepenuhnya otomatis, dengan orkestrasi yang bisa menyembuhkan diri sendiri.
- Berbasis metadata, memudahkan pengelolaan data lineage.
- Serverless, meminimalkan beban operasional.
- Dibantu AI, untuk mengoptimalkan kinerja dan deteksi anomali secara otomatis.
Seiring perkembangan AI dan machine learning, data engineering tetap menjadi fondasi utama, karena AI hanya sebaik kualitas data yang dimilikinya.

🧾 Kesimpulan
Membangun data pipeline modern adalah kombinasi antara seni dan ilmu. Kuncinya adalah menyeimbangkan kecepatan, skalabilitas, dan reliabilitas sambil tetap fokus pada kebutuhan bisnis.
Kesimpulan penting:
Data pipeline yang kuat mengubah kekacauan menjadi kejelasan.
Dalam artikel berikutnya, kita akan membahas ETL vs ELT, Data Lake vs Warehouse, dan alat penting yang wajib dikuasai Data Engineer di tahun 2025 — untuk membantu Anda membangun sistem data yang lebih cepat, lebih pintar, dan lebih efisien.
Leave a Reply