🧭 Introduction: The Lifeblood of the Data-Driven World
Every modern business — from startups to global enterprises — depends on one thing: data flow.
But raw data is messy, scattered, and often useless until it’s properly collected, processed, and transformed into insight.
That’s where a data pipeline comes in — the invisible system that transports, cleans, and organizes data so analysts, data scientists, and business teams can make real decisions.
In this article, we’ll explore how to design a modern, scalable data pipeline, what tools are essential, and how it all connects from ingestion to insight.

⚙️ What Is a Data Pipeline?
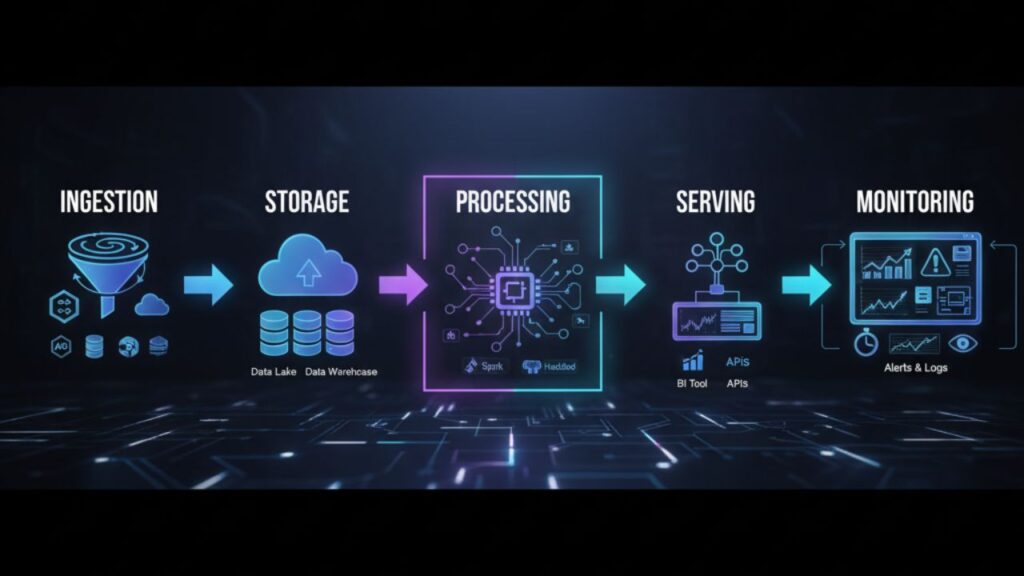
A data pipeline is a sequence of steps that moves data from one system to another, transforming it along the way. Think of it as a factory assembly line — raw materials (data) enter one side, and finished products (insights) come out the other.
Common Stages:
- Ingestion: Collecting data from sources (databases, APIs, IoT, logs).
- Storage: Saving it in a data lake or warehouse.
- Processing: Cleaning, transforming, and enriching.
- Serving: Making data available for analytics or machine learning.
- Monitoring: Ensuring reliability and accuracy.
🧩 The Key Components of Modern Data Pipelines
Modern data pipelines are built with scalability, automation, and resilience in mind. Let’s look at each layer in detail.
1. Data Ingestion
Ingestion is the process of bringing data into your system. It can be:
- Batch ingestion: Periodic uploads (e.g., nightly job from CRM).
- Streaming ingestion: Real-time (e.g., Kafka, Kinesis, Pub/Sub).
2. Data Storage
Data can be stored in multiple formats and layers:
- Raw Zone: The unaltered source data.
- Processed Zone: Cleaned and formatted data.
- Analytics Zone: Ready for dashboards or AI.
Typical storage options include Amazon S3, Google Cloud Storage, Azure Data Lake, or on-prem solutions like HDFS.
3. Data Transformation
Transformation (ETL or ELT) cleans and reshapes data to fit business needs. Popular tools include Apache Spark, dbt, and AWS Glue.
4. Data Orchestration
This coordinates how and when pipeline tasks run. Apache Airflow and Prefect are the most widely used.
5. Data Delivery
Finally, the transformed data is delivered to warehouses (e.g., Snowflake, BigQuery) or BI tools (e.g., Power BI, Looker Studio).

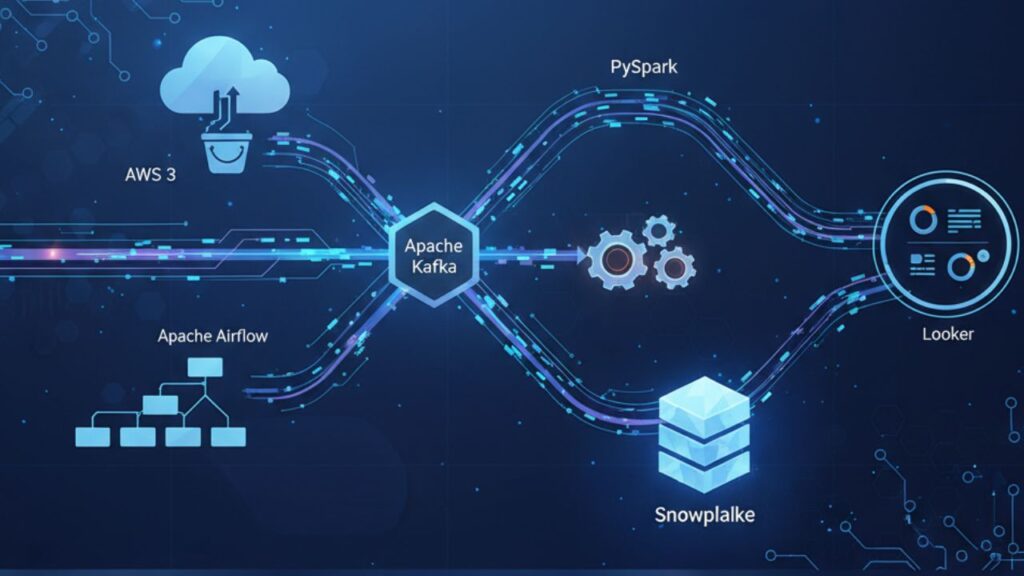
🧮 Example Architecture: Airflow + Spark + Snowflake
Let’s design a simple, scalable architecture that’s both cloud-ready and cost-efficient.
Pipeline Flow Example:
- Ingestion: Kafka streams real-time event data.
- Storage: Data lands in AWS S3 (Raw Zone).
- Transformation: Spark jobs clean and aggregate.
- Orchestration: Airflow DAG schedules all jobs daily.
- Warehouse: Final data stored in Snowflake for BI use.
- Analytics: Looker dashboards visualize results.
This approach separates each concern — making your system modular, testable, and fault-tolerant.
⏱️ Batch vs. Real-Time Pipelines
Data pipelines can operate in batch or real-time mode — the choice depends on your business requirements.
| Mode | Use Case | Example Tools |
|---|---|---|
| Batch | Nightly sales reports, monthly summaries | Airflow, Spark, dbt |
| Real-Time | Fraud detection, IoT sensors, stock trading | Kafka, Flink, Kinesis |
Many organizations use a hybrid architecture — batch for historical data, streaming for live analytics.
🔮 The Future of Automated Data Flow
Tomorrow’s data pipelines will be:
- Fully automated, with self-healing orchestration.
- Metadata-driven, enabling data lineage and governance at scale.
- Serverless, reducing operational overhead.
- AI-assisted, automatically optimizing workflows and detecting anomalies.
As AI and machine learning continue to evolve, data engineering will remain the foundation — because AI is only as good as the data that feeds it.

🧾 Conclusion
Building a modern data pipeline is both an art and a science. It’s about balancing speed, scalability, and reliability while keeping the business needs in focus.
The key takeaway:
A strong data pipeline turns chaos into clarity.
In the next articles, we’ll dive deeper into ETL vs ELT, Data Lake vs Warehouse, and the essential tools every Data Engineer must master in 2025 — all to help you build better, smarter, and faster data systems.
Leave a Reply